India is a land of diversity including of linguistic diversity. This proves difficult to provide services to citizens in their preferred language a mammoth task particularly when there are also inter-state migrants who all speak different languages.
In this regard, my observation is that there is a very high degree of compatibility of Transcription & Transliteration in Indian languages – principally on account of 1-to-1 mapping of Graphenes (the smallest unit of writing) of Indian languages coupled with phonetic word construction by merger of consonants and vowels in a similar fashion. This is an under-appreciated fact of Indian languages where ‘politically’ the weight is put on diversity and not similarities and compatibility.
This can be useful in development of Tech-supported applications for delivery of eGovernance Basic Services like for example
An Aadhar Card issued in Marathi can be transliterated to Tamil or Odia or any other Indian Language and vice versa.
A Birth Certificate in Bangla to Gurumukhi (Punjabi) and vice versa.
A Vehicle Registration or Driving License in Malayalam to Assamese.
And many like these.
For example in commercial startup space,
a Station Name in case of a Travel portal once transliterated properly in Gujarati can be transliterated & transcripted into all India Languages and vice~versa.
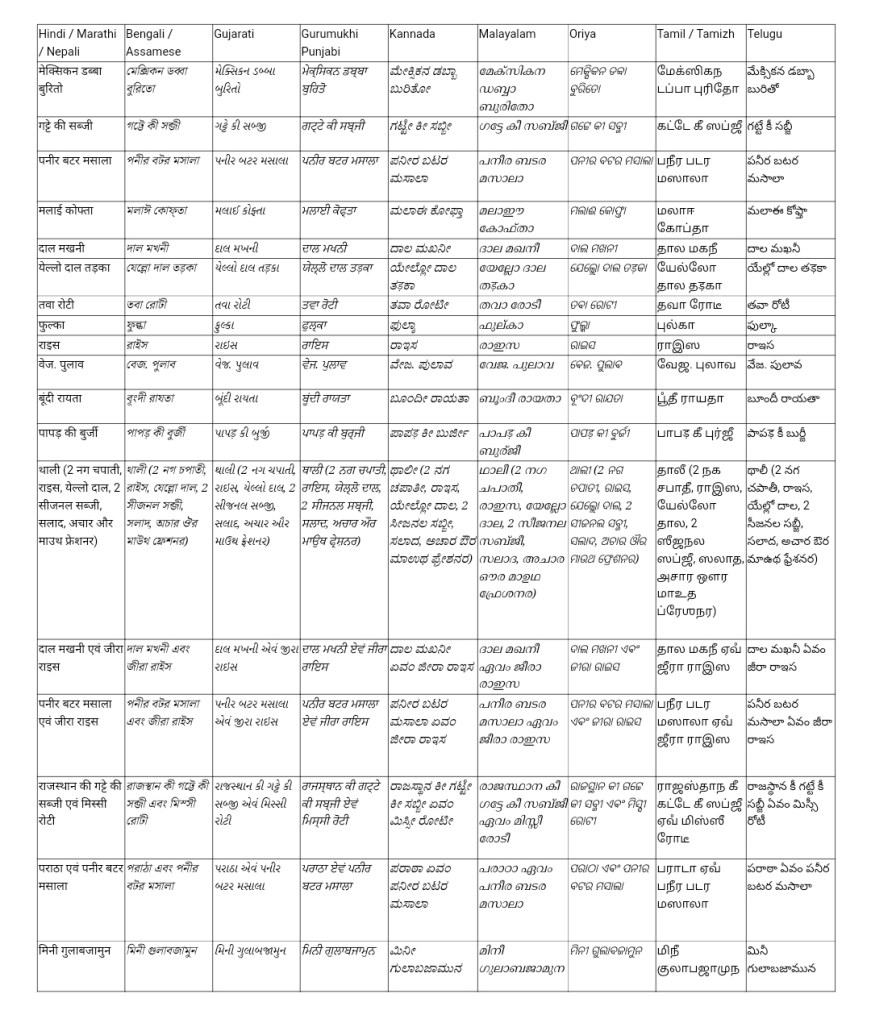
or on a food delivery portal, a restaurant menu item once transliterated in Odia can be transliterated & transcripted into all Indian languages and vice~versa.
My point of emphasis in these examples is that these represent structured Data Entry – it can be identified what needs to be translated (basically field labels) & what needs to be transcripted and transliterated (data entered).

On this basis I have also prepared a short 10-slide presentation (pdf) on A Methodology on Multi-lingual Applications for Indian users in Indian languages which may be of interest to Application Developers and Startups.
A sample restaurant menu transcripted from Devanagri Hindi into 8 other regional languages.